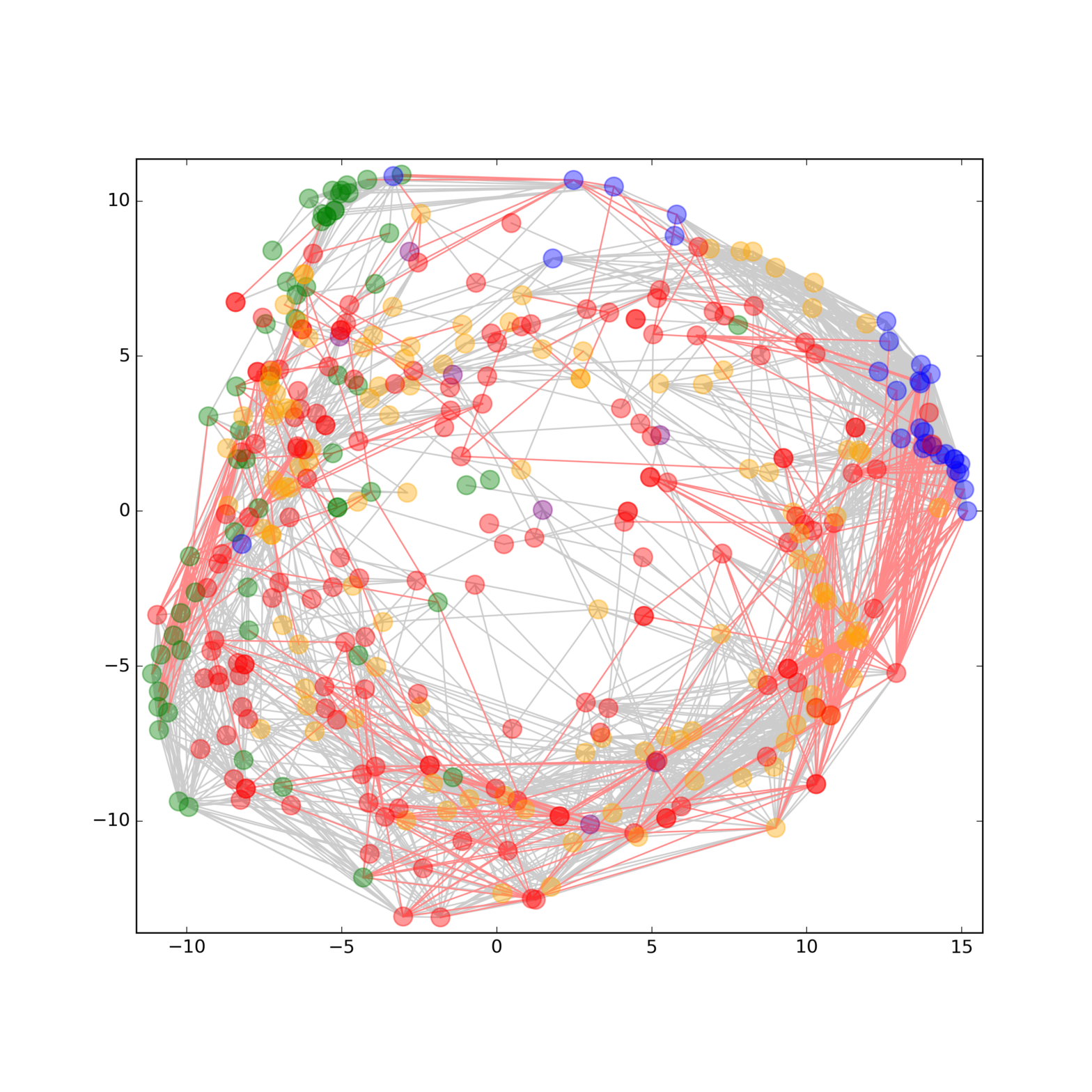
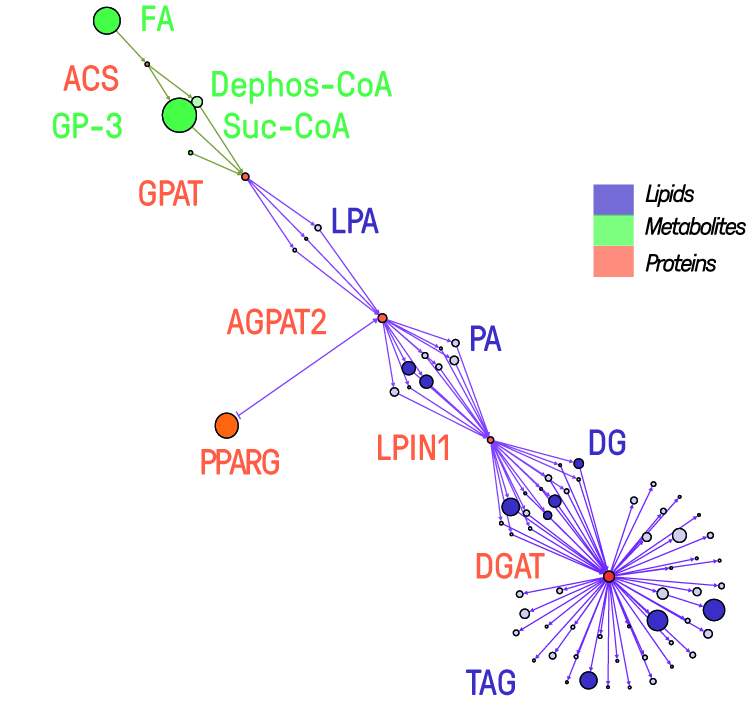
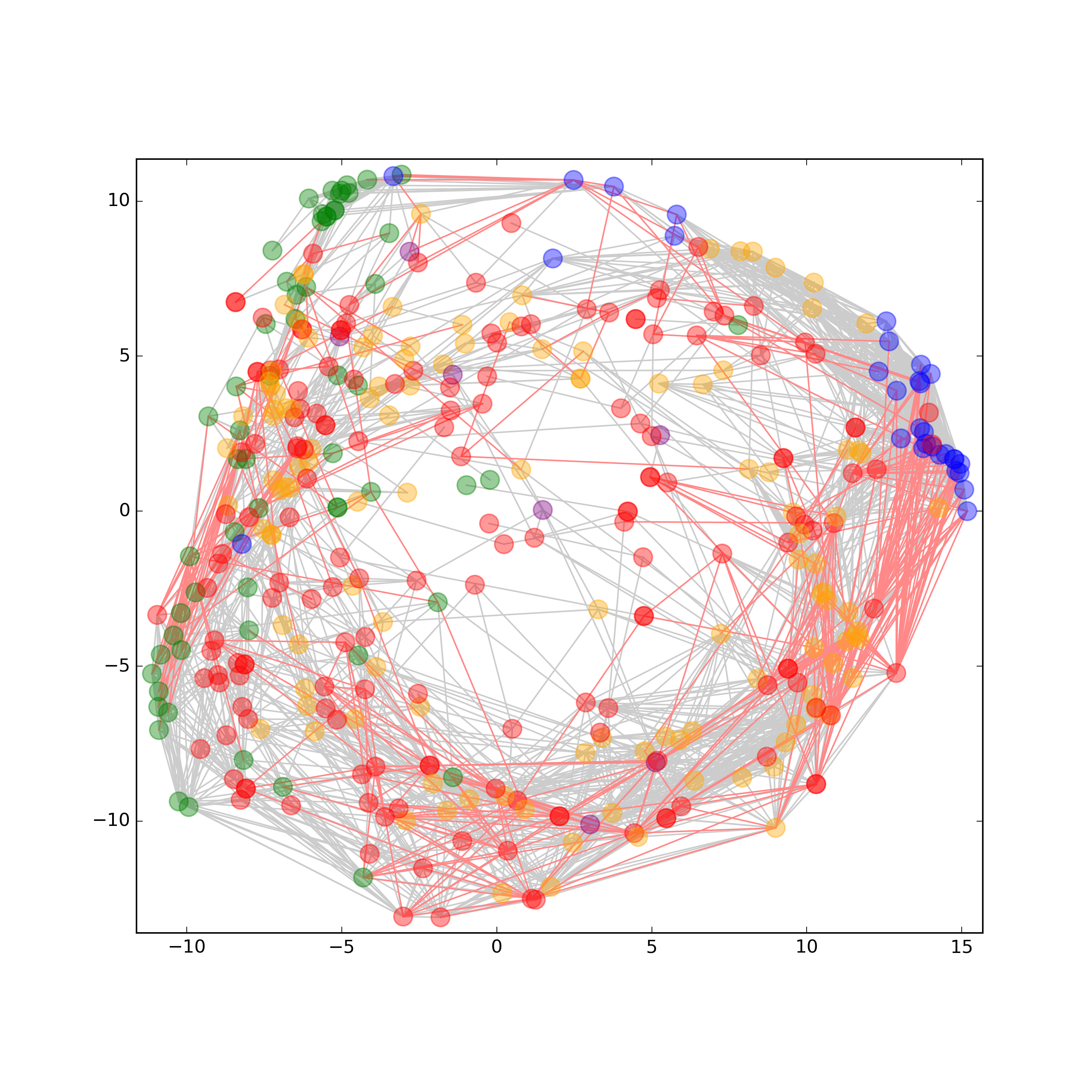
 Metabolic dysfunctions are not only highly correlated with insulin resistance and diabetes, but are also associated with a 10 fold higher risk to develop Alzheimer’s disease. The proposed project joins forces between two Leibniz institutions with different expertise to establish a unique research platform for Translational Neuroscience. Here, we will break ground by introducing lipidomics to the field of synapse biology, by investigating insulin resistance in conjunction with high Abetaload and by studying the effect whether synaptic disease states result in an altered lipid composition that in turn leads to synaptic dysfunction in brain.
Metabolic dysfunctions are not only highly correlated with insulin resistance and diabetes, but are also associated with a 10 fold higher risk to develop Alzheimer’s disease. The proposed project joins forces between two Leibniz institutions with different expertise to establish a unique research platform for Translational Neuroscience. Here, we will break ground by introducing lipidomics to the field of synapse biology, by investigating insulin resistance in conjunction with high Abetaload and by studying the effect whether synaptic disease states result in an altered lipid composition that in turn leads to synaptic dysfunction in brain.